会议之后,将录音转文字是非常重要但又痛苦的事情,由于录音的信息密度非常不均匀,重点分散在各个时间戳上面,完整地听完并整理成文字将耗费大量的时间。 因此直接将语音准确地转成带时间戳的文字,可以帮助我们快速锁定重点内容进行理解,是提高效率的重中之重。好消息,OpenAI推出了开源自动语音识别 (ASR) 模型 Whisper,我们可以自己搭建本地语音转文字大模型,准确率较高,不吃GPU(没GPU速度慢一些)。
效果:
windows 10 CMD
软件安装
-
根据官网说明编译,或者windows直接下载我提供的压缩包,提供了
whisper+ffmpeg软件,解压即可。链接:https://pan.baidu.com/s/17VMcDcfw0GsKoq_UEvOuHQ 提取码:1234
-
下载训练好的大模型
ggml-medium.bin(推荐这个中等模型,1.40GB不会很大,准确率也不会低)。
使用
-
预处理,
whisper.cpp只支持16bit WAV文件,因此通过ffmpeg先将视频、录音等其他格式的文件统一转成此音频格式:D:\ffmpeg\bin\ffmpeg.exe -i D:\5-13-10点19分.m4a -ar 16000 -ac 1 -c:a pcm_s16le output.wav -
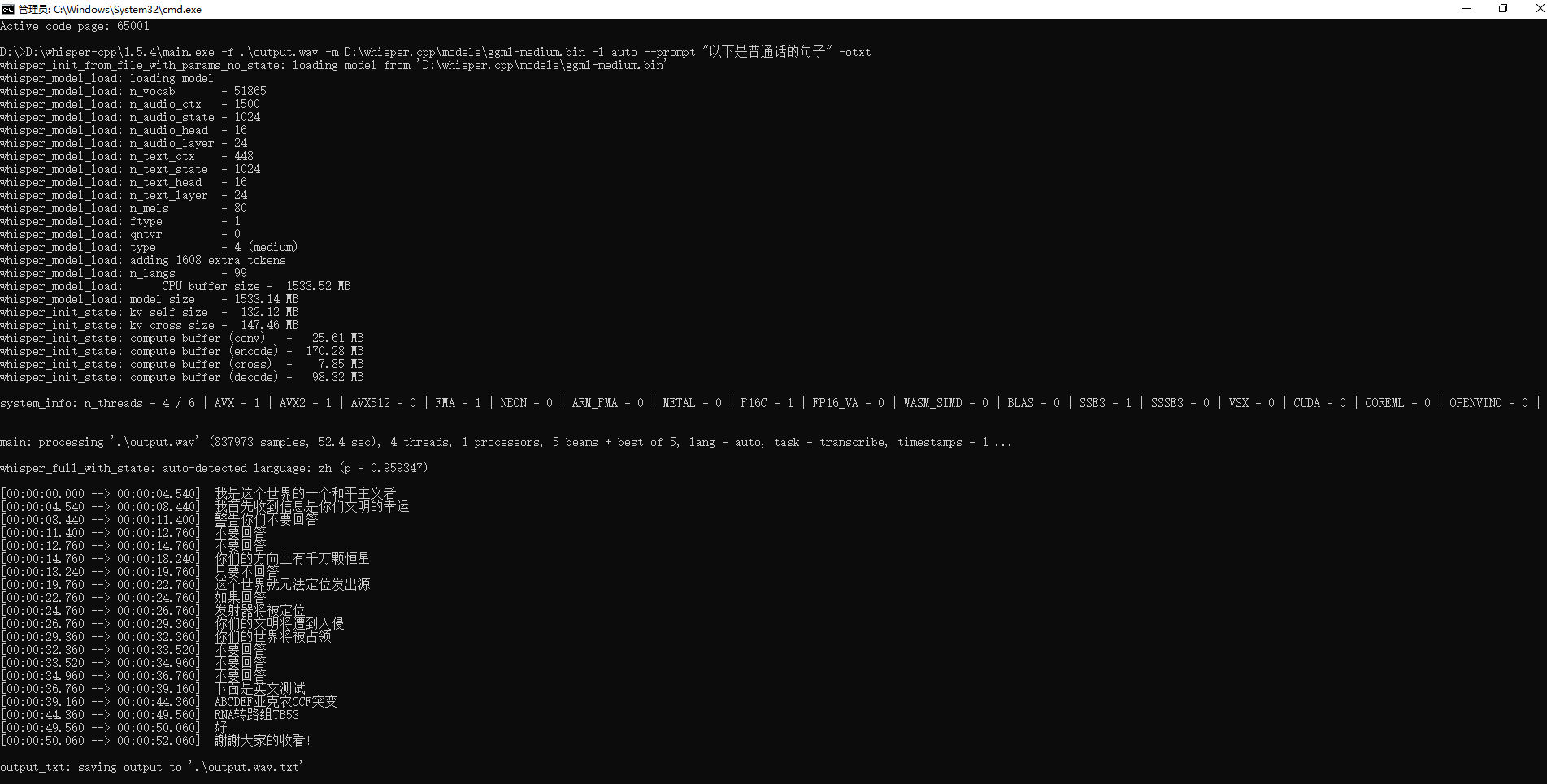
内容转文字[1]:
chcp 65001 # 避免乱码 D:\whisper-cpp\1.5.4\main.exe -f .\output.wav -m D:\models\ggml-medium.bin -l auto --prompt "以下是普通话的句子" -otxt
-
由于可以识别各种语言,设置提示词避免输出繁体中文;2.其它参数解释见whisper.cpp。